An API-First Approach to Real-Time Personalization with Miso

At Miso.ai, we operate by a simple but strict modus operandi: build tools that are as open, extensible, and decentralized as possible so that any product team can unlock the creative opportunities of real-time personalization.
In our early startup days (Yes, I know we’re still a startup) we would have defined ourselves as enterprise-first. It might seem counterintuitive in the heady world of SaaS B2B startups that start off with developers and small businesses, but we were fortunate enough to be able to work with household names right out of the gate, like O’Reilly, and Tundra, and a few we’ve had to agree to never mention in public (or their lawyers will descend on us in the dead of the night…). The distinction of being enterprise-first and building for scale influenced the way we thought about software design — building tools that were massively scalable and aligned with the engineering and product management cultures of very large organizations.
This led to our commitment to make Miso an API-first platform. An API-first approach necessitates that APIs are “first-class citizens” in that they are the primary way that clients interact with our real-time personalization models. From uploading real-time clickstream data to fulfilling search requests and Frequently Bought Together product shelves, there’s an API designed for the task. Most importantly, abiding by API-first principles means that our APIs are carefully designed, well documented, and high throughput. It also allows us to do proper versioning and feature flagging, so you don’t end up like the XKCD below:

In our experience, being API-first has made the implementation process very straightforward for our partner developer teams. But it’s also given us a ton of flexibility in supporting our partners with a range of integration and implementation methods. From building and launching our own client-side SDK, to enabling direct integrations with customer data platforms like Segment, and even a 1-click install with Shopify, we’ve seen tremendous speed and leverage on being API-first. And while our 3rd party integrations and client-side SDK are all excellent patterns of working with Miso’s real-time personalization platform, they are, by definition, an abstraction layer built on top of Miso’s bread-and-butter APIs, designed to complement various levels of architectural complexity.
So if all these implementation methods already exist, who exactly are we building our direct integration with REST APIs for? In practice over the last two years, it’s really more about the approach to product management and engineering a team is taking. We’ve repeatedly seen that the teams who use our APIs directly to turn on real-time personalization value, at a product engineering level, the ability to directly parameter control, feature flag, and A/B test the search and rec API calls they are making. And they’re deeply invested in building great data infrastructure and internal microservices to support turning on services like Miso in the first place.
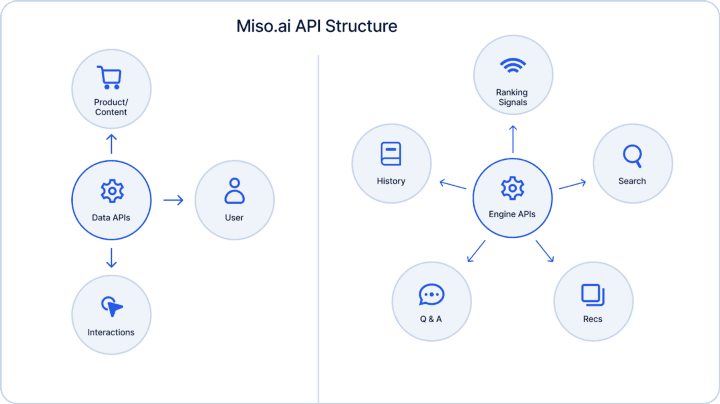
Miso’s API Structure
Miso’s APIs are categorized into two main groups: Data APIs and Engine APIs. The Data APIs’ primary purpose is to send data (via JSON payload) to Miso. This could be for real-time user clickstream logs, updating the product catalog, or optionally providing any additional data on user preferences, like results from a taste survey. In other words, this is how you put data into Miso’s personalization engines, for generating real-time user embeddings and subsequent engine re-training.
To take data out of Miso’s personalization engines and serve it to your customers in the presentation layer, you’d use the Engine APIs. Each Engine API (and their endpoints) generates a different type of personalization result, so depending on how deep personalization is embedded into your user experience, you may use one or all the APIs. For example, the Search API takes a keyword (or less with zero-shot search and autocomplete) as input and returns a rank-sorted list of relevant search results, while the Recommendation API can populate product shelves like “You May Also Like” and “Categories You May Like”. There’s a plethora of use-cases that the Engine APIs can be utilized for that you can check out on our Recipes page.
On a more technical level, a typical call pattern for our API (in this case, the Search API) looks like below:
POST /v1/search/search { “q”: “jeans”, “user_id”: “user-123” }
This API request will return results for a user that searched for “jeans”. Miso requires that the user id (or anonymous id) be included in every request because the returned products will be rank-sorted not only by their relevance to the keyword, but also by the likelihood of resulting in a conversion (based on the real-time vector embeddings of the user that is performing the search).
On the other hand, to send clickstream events as they occur, you would need to send Miso details of the event within the payload of the interactions API. It might look something like this:
POST /v1/interactions {
"data": [
{
"type": "product_detail_page_view",
"product_ids": [ "movie_456" ],
"user_id": "user_123",
"timestamp": "2021–08–24T14:15:22Z" }
]
}
I’ll avoid going too deep into the rabbit hole and leave you with our official API documentation if you’re interested in learning more about the Miso API call patterns.

Is a backend API implementation right for you?
As I mentioned earlier, Miso has several recommended implementation patterns you can use, depending on the complexity of your tech stack. On one side of the spectrum, you have our 1-click integration with Shopify, which enables storefronts on the platform to automatically send real-time clickstream data and product catalog updates to Miso as soon as they install the app. The backend API implementation we’ve been discussing in this post (using your backend server to access Miso’s Data API) is towards the opposite end — useful for organizations that already have a homegrown, backend systems architecture for collecting, storing and streaming clickstream events in the first-place. Here’s one example of what it might look like:
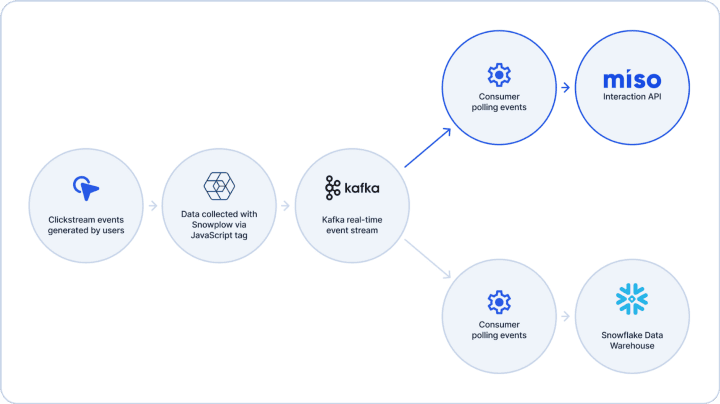
In this theoretical system architecture, an organization is collecting user clickstream data from their site using a Snowplow tag. Those events are sent to a real-time messaging service like Kafka, where consumers can subscribe to a topic to pull those events into downstream applications, like a Snowflake database. In this example, setting up a real-time data pipeline for Miso would entail creating a new consumer, transforming the event logs to Miso’s interaction schema (if necessary) and then sending them to Miso via HTTP requests.
Note: To be clear, you don’t have to use Snowplow or Kafka in order to work directly with Miso’s APIs. I use them in my example because they are vetted open-source solutions. You may already have another clickstream data collection tool and event streaming pipeline in place, and the Miso onboarding process will be very similar.
Here’s an pseudo-pythonic example of what it would look like.
First, we’d need to set up a new consumer to subscribe to the clickstream events coming out of the Snowplow topic. The primary configuration would include providing the bootstrap server address, group ID, and initial partition offset.
consumer = Consumer({
"bootstrap.servers": YOUR_BOOTSTRAP_SERVER,
"group.id": "miso-group",
"auto.offset.reset": "largest"
})consumer.subscribe(["YOUR_SNOWPLOW_EVENT_TOPIC"])
Next, we’ll start pulling messages from the topic using the poll() method, decode it from a string to a JSON format, and then transform the data to match Miso’s interaction API schema. Finally, we’ll append the record to a list called chunk that holds a batch of records to upload.
messages = consumer.poll(1.0)
for message in messages:
origin_message = json.loads(message.value().decode("utf-8"))
miso_interaction_record = {
"user_id": origin_message["user_id"],
"type": "product_detail_page_view",
"timestamp": origin_message["timestamp"],
}
chunk.append(miso_interaction_record)
The last step is to send the batch event data (groups of 10) to Miso via a POST HTTP request.
if len(chunk) == 10:
requests.post(
method="POST",
url="https://api.askmiso.com/v1/interactions",
json={"data": chunk},
params={
"api_key": "YOUR_MISO_API_KEY",
},
)
logger.info("Uploaded 10 interaction records to Miso")
chunk.clear()
Putting it all together, the full process looks like this:
consumer = Consumer({
"bootstrap.servers": settings.KAFKA_HOST,
"group.id": "outside-miso-group",
"auto.offset.reset": "largest"
})consumer.subscribe(["YOUR_SNOWPLOW_EVENT_TOPIC"])chunk = []
while True:
messages = consumer.poll(1.0)
for message in messages:
origin_message = json.loads(message.value().decode("utf-8"))
miso_interaction_record = {
"user_id": origin_message["user_id"],
"type": "product_detail_page_view",
"timestamp": origin_message["timestamp"],
}
chunk.append(miso_interaction_record)if len(chunk) == 10:
requests.post(
method="POST",
url="https://api.askmiso.com/v1/interactions",
json={"data": chunk},
params={
"api_key": "YOUR_MISO_API_KEY",
},
)
logger.info("Uploaded 10 interaction record to Miso")
chunk.clear()
Closing Thoughts
If your organization’s architecture looks similar to what I described above, where you currently collect real-time clickstream data (whether it be via Snowplow, MetaRouter, or similar), it makes sense to just add Miso as an additional destination. Otherwise, one of the other implementation patterns, like using our client-side SDK, make a lot more sense to use.
We’ve processed over 3.5 billion personalized search and recommendation requests so far and we’re rapidly climbing. A major aspect of serving real-time, dynamic content via our REST APIs has been maintaining low latency and high availability. I’d say we’ve been successful so far in this regard, with an average latency of less than 100ms on API calls and ~99.9999% uptime. Miso’s clusters are infinitely horizontally scalable since it’s built on top of AWS EC2 instances. We also have a dedicated Server Reliability Engineering (SRE) team that closely monitors our API performance and proactively performs capacity planning for major shopping days like Black Friday and Super Bowl Sunday.
Before I close out, I’d like to give a shoutout to Lucky Gunasekara for his editing expertise and Stian Johannessen for his design work. If there’s anything in the Miso-sphere that you’re curious about and want us to unpack, drop us a line on our contact form or at hello@askmiso.com. We’d love to hear about what you’re working on and how we can help!
